欢迎各大佬,大牛对本文指正,也希望本文能对各位有所帮助
本篇很多地方借鉴英雄哪里出来的博客%%%
一、基本概念
- 线段树是一棵二叉搜索树,它储存的是一个区间的信息。
- 每个节点以结构体的方式存储,结构体包含以下几个信息:每个节点以结构体的方式存储,结构体包含以下几个信息:
(1). 区间左端点、右端点
(2). 区间所代表的值
(3). 该节点的子节点
- 线段树的基本思想:二分。
- 线段树一般结构如图所示:
假设数据为4个数,则树应是这样
- 由上图可知,每个节点的
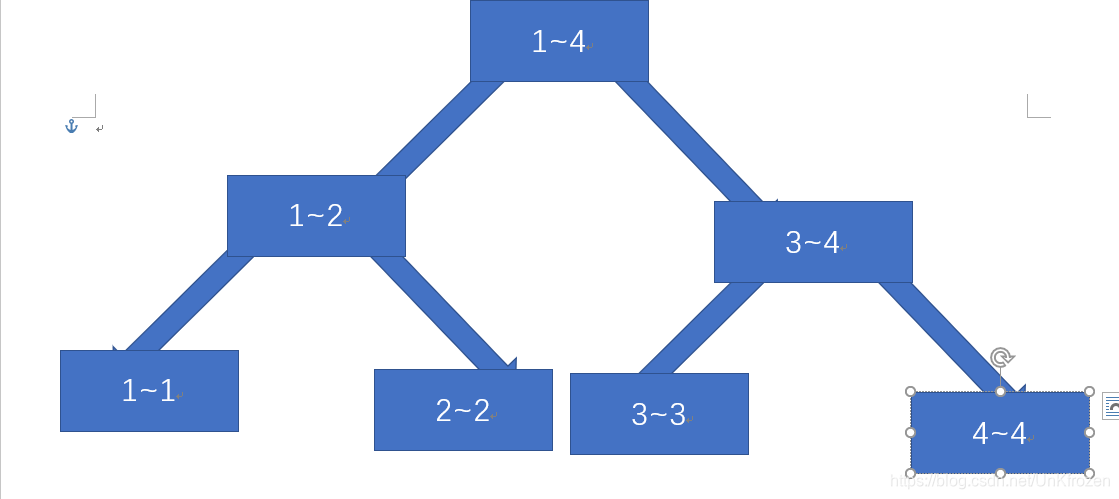
每个节点的左孩子区间范围为[left,mid],右孩子为[mid+1,right]
二、代码实现与基本操作
0.基础数据结构
1 |
|
1.建树 built函数
1 | Node built(int left, int right) |
除了建树,相应关闭树的函数为:
1 | void close(Node p) |
非常需要注意的一件事,每次用指针建立树的时候,请务必写一个关闭清理申请的内存的函数
2. 单点查询
(1).查找k位置的数据
1 | int find(Node p, int k) |
3.单点修改
(1).知道点所在位置,修改该点处值
1 | int update(Node p, int x,int k) //对x位置的值,进行k值的变动 |
4.区间查询
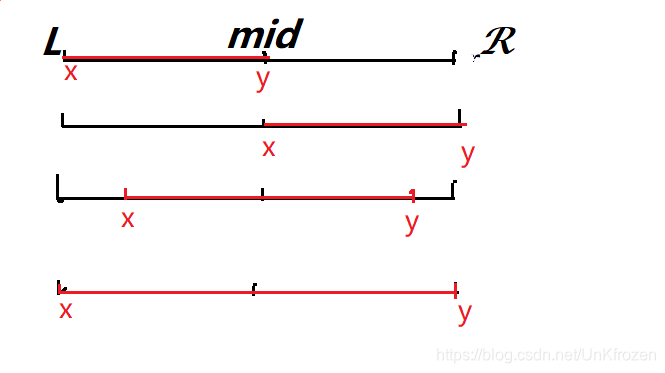
所给区间仅可能为上图四种情况。
通过一定操作,我们都可以将上三种,全部转换为最后一种直接输出。
闲话少说,代码实现
1 | int find(Node p, int x,int y) //注,这里假设任意x,y,都有x<y |
5.区间修改
1 | int update(Node p, int x, int y, int k) //设区间为[x,y],修改的值为k |
三.优化
(一). Lazy-Tag懒标记
我们考虑一下区间改值的过程:当更改某个区间的值的时候,子区间也跟着更改。显然,在大数据下,这样操作会导致TLE。
怎么办?
这时我们就引入一个优化方法,叫做Lazy-Tag懒标记。
何为懒标记呢?顾名思义,就是用来偷懒的减少修改时消耗时间的。即:
当我想要对某一区间的所有元素都+k时,在修改该区间节点时,对其打上标记lazy,并记lazy为k,修改该节点的值为+区间长度*k,立刻return,而不将该节点下面的所有子节点一一修改。
思想实现
如图示:1~4的值分别为1,2,3,4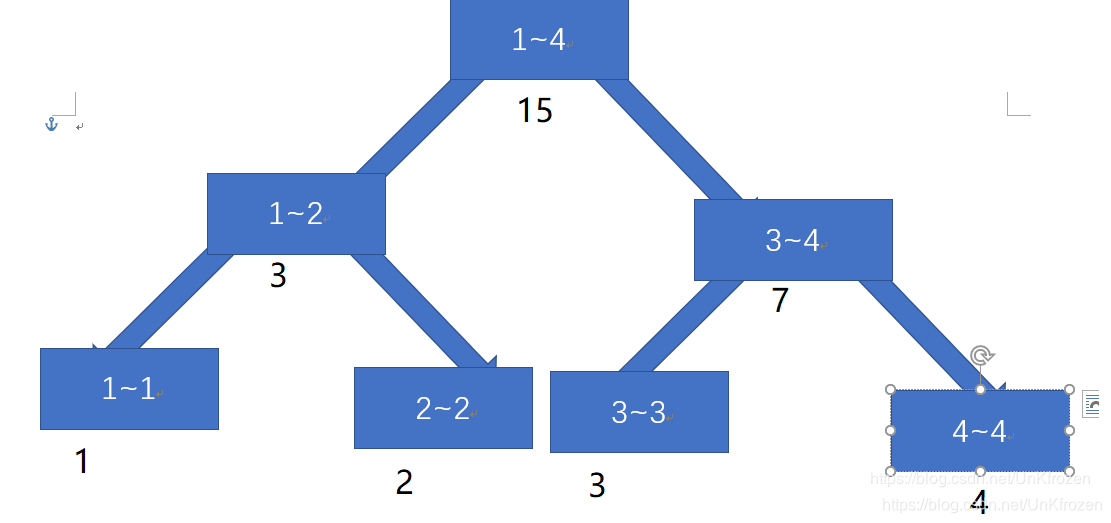
我们选择对[1,2]区间进行修改,要求改区间所有值+2,则:在区间[1,2],打上标记lazy=2,并修改其值为3+(2-1+1)2,直接返回,并不对其子节点进行修改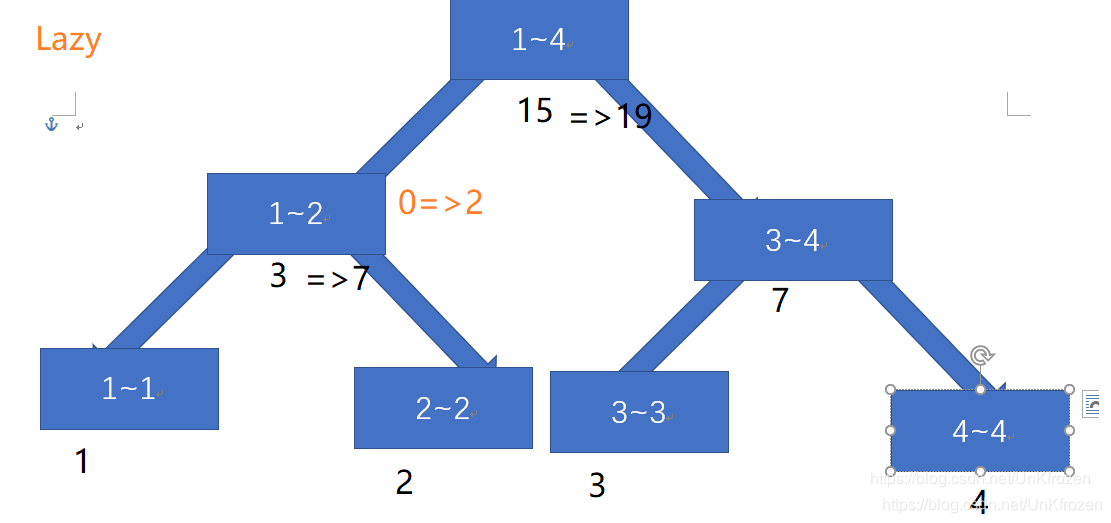
当我们再次对[1,2]区间修改时,并要求区间内所有的值+1,则:由于[1,2]有标记lazy=2,于是我们将lazy标记向其子节点传导,并修改其子节点的值。再在[1,2]区间打上lazy=1,修改值为(2-1+1)1,返回。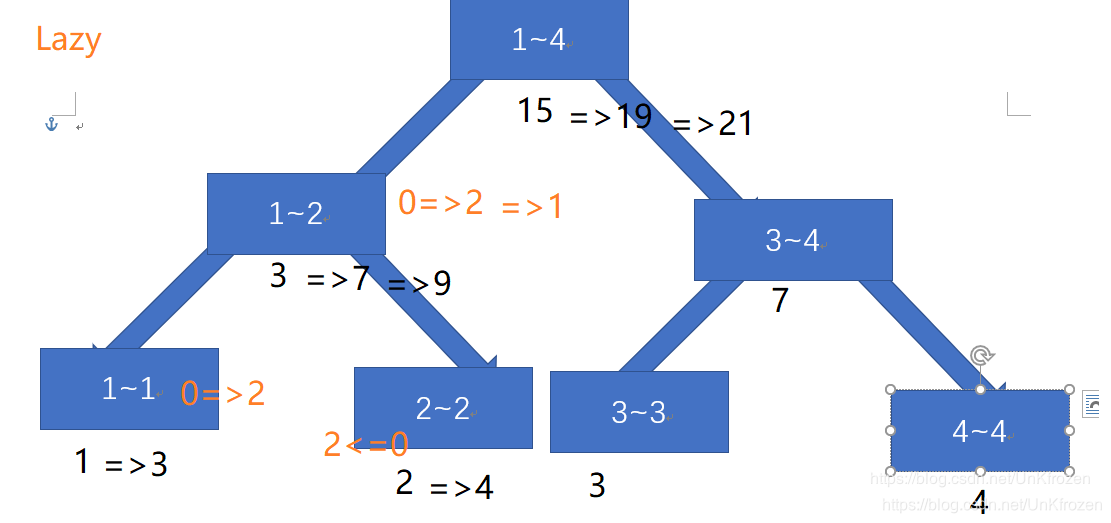
代码实现
0.核心代码 pushdown
1 | void pushdown(Node p) |
1.树本体
1 |
|
2.建树
1 | Node built(int left, int right) |
3.单点查询和单点修改无改变
4.区间查询
1 | long long find(Node p, int x, int y) //区间查询 |
5.区间修改
1 | int update(Node p, int x, int y, int k) //区间修改 |
(二). 离散化
离散化是一个听起来很高大上的方法.
其实做起来很简单.当然如果想高深的话,自然也拦不住
其实就是将一串数据储存到数组中,不将数据本身作为键值,而是选择使用数组的下标作为键值.
形象的,$1,2,3,10000000$这四个数,保存在数组$a[]$中,相对应的下标为$1,2,3,4$就可以减少空间的开支.
数组实现
如果你觉得这个代码很熟悉!
那就当我抄的吧,嚯嚯嚯
洛谷线段树1:
1 |
|
洛谷线段树2:
1 |
|